Slurm Installその後5-続き. slurmstepd: error
はじめに
前回エントリでは、Container Bundleを使ってsbatchでのコンテナ実行を試してみました。
その際に以下のエラーが発生していましたが、原因が特定できたので情報を残しておこうと思います。
エラーの状況は以下でした。
[john@master ~]$ sbatch --container /mnt/share/john/centos_image --wrap 'grep ^NAME /etc/os-release' Submitted batch job 779
[john@node1 ~]$ cat slurm-779.out NAME="CentOS Linux" slurmstepd: error: _try_parse: JSON parsing error 71 bytes: boolean expected
出力にslurmstepd: error: _try_parse: JSON parsing error 71 bytes: boolean expectedが出てしまっているというものでした。
前回エントリ
目次
エラーについて
slurmd.log
ジョブが実行されたノード(Node1)のslurmdログ/etc/slurm/slurmd.logの抜粋を貼っておきます。
ログを確認したところ、Node1ではジョブ実行時に以下が出力されていました。
[2022-11-23T08:49:26.728] debug2: Finish processing RPC: REQUEST_TERMINATE_JOB [2022-11-23T08:49:26.747] [871.batch] debug: _get_container_state: RunTimeQuery rc:256 output:time="2022-11-23T08:49:26Z" level=error msg="container does not exist" [2022-11-23T08:49:26.748] [871.batch] error: _try_parse: JSON parsing error 71 bytes: boolean expected [2022-11-23T08:49:26.748] [871.batch] debug: container already dead
ジョブログslurm-779.outに「...JSON parsing error...」がerrorレベルで出力されていますが、その直前でmsg="container does not exist"というメッセージが、また抜粋の最終行にも、msg="container already dead"というdebugレベルのメッセージが出力されていました。
※ /etc/slurm/slurm.confでSlurmdDebugをdebug以上を指定しておく
Kill Container
このmsg="container already dead"の出力元ソースコードを確認したところ、src/slurmd/slurmstepd/container.cに含まれる_kill_container()から呼ばれる_get_container_state()が該当箇所にあたりました。
この部分はどうやら/etc/slurm/oci.confにRunTimeKillを指定していた為、その挙動を実現する為の実装箇所のようです。
<再掲>
ContainerPath=/home/john/local_image CreateEnvFile=False RunTimeQuery="runc --rootless=true --root=/tmp/ state %n.%u.%j.%s.%t" RunTimeKill="runc --rootless=true --root=/tmp/ kill -a %n.%u.%j.%s.%t" RunTimeDelete="runc --rootless=true --root=/tmp/ delete --force %n.%u.%j.%s.%t" RunTimeRun="runc --rootless=true --root=/tmp/ run %n.%u.%j.%s.%t -b %b"
以上から読み取れることはとてもシンプルですね。
コンテナの停止(runc...kill...)を行おうとしたけど...既にコンテナは停止していた(container already dead)
ということですね。
サンプルで作成したContainer bundleは、Slurmジョブの中でrunc ...run...でコンテナ生成&実行されていますが、その後すぐに停止するコンテナです。
もともとはdockerイメージcentos:latestをpullしてContainer bundle化して、grep ^NAME /etc/os-releaseを実行するだけのものでした。
Slurmで起こっていたことを自分でruncコマンドで再現すると、概ね以下のような具合です。
[john@master john]$ runc run test --bundle ./centos_image NAME="CentOS Linux" [john@master john]$ runc list ID PID STATUS BUNDLE CREATED OWNER [john@master john]$ runc kill test ERRO[0000] container does not exist
runc runの後でrunc listをたたいても、terminate済なのでコンテナ情報はありませんし、当然、runc killするとエラーメッセージが出力されます。container does not existも先程の/etc/slurm/slurmd.logの出力とあっていますね。
...というところが原因でした。
今回のような事象に出会うかはContainer bundle化するコンテナのつくりによるところもあるので、
- すぐに終了するコンテナなのか?
- 起動しつづけるコンテナなのか?
- また、oci.confでのRunTimeコマンドの指定のやり方
など、Slurmで自分が使うContainer Runtimeにあわせて、設定を確認しておいた方が良さそうですね。
動かしてみる
では、今回のエラーの解消を確認してみたいと思います。
oci.confの変更
今回のサンプルそのままで簡単にやりたかったので、以下のようにrunc runコマンドにdetachオプション(-d)をつける形で実行してみます。バックグラウンドで起動させておく形です。
/etc/slurm/oci.conf
RunTimeRun="runc --rootless=true --root=/tmp/ run %n.%u.%j.%s.%t -b %b"
RunTimeRun="runc --rootless=true --root=/tmp/ run %n.%u.%j.%s.%t -d -b %b"
反映
oci.confの変更が済んだらノードに撒きます(Node1への例)。
scp -p /etc/slurm/oci.conf node1:/etc/slurm
忘れずにslurmd, slurmctldを再起動します。 ※今回はNode1だけ
sudo systemctl restart slurmd
sudo systemctl restart slurmctld
実行
前回エントリと同様にsbatchを投げてみます。
[john@master ~]$ sbatch --container /mnt/share/john/centos_image --wrap 'grep ^NAME /etc/os-release' Submitted batch job 875
COMPLETEDしているようです。
[slurm@master ~]$ sacct --allusers --job 875 JobID JobName Partition Account AllocCPUS State ExitCode ------------ ---------- ---------- ---------- ---------- ---------- -------- 875 wrap partition+ chemistry 1 COMPLETED 0:0
では、Node1で出力されたログを確認します。
[john@node1 ~]$ cat slurm-875.out NAME="CentOS Linux" [john@node1 ~]$
→想定した出力のみです。slurmstepd: error: _try_parse: JSON parsing error 71 bytes: boolean expected が出なくなったことが確認できました。
ということで以上、前回エラーの解決でした。
最後に
初見で「slurmstepd: error: _try_parse: JSON parsing error 71 bytes: boolean expected」だけをみたときは?でした。
エラーログを落ち着いて確認すれば難しい問題ではないかもしれませんね。
Slurm Installその後5. Slurm with OCI Container Runtime (Rootless Docker)
はじめに
今回はSlurmでのコンテナ起動設定をやってみたいと思います。
コンテナといえば思い浮かぶのはDockerが一般的ですが、root権限でdockerdを常駐させる仕組みです。
root権限での操作は資源共有を行うHPCジョブスケジューラ環境にとっては深刻なセキュリティリスクで、そのままSlurmでは使えません。
ただし、OCI準拠コンテナランタイムを非特権で動かすのはSlurmでネイティブサポートされているとの事なので、今回はsbatch(srun,salloc)に実装された「--containerオプション」(21.08〜)を使って、コンテナ実行ができるか?
試してみたいと思います。
ちなみに...
Slurmを含めHPC環境でのコンテナワークロード利用は「Singularity」がデファクトスタンダードな世の中な気がしています。が、少し前に開催されたSLUG'22でpodmanなども紹介されてましたし、Slurmでのコンテナワークロード利用環境は今後充実しそうなので個人的には注目したい所です。
(scrunの実装など、色々楽しみですね!!)
https://slurm.schedmd.com/SLUG22/OCI_Containers_with_scrun.pdf
目次
Container with Slurm
今回の作業は主に、以下の公式ドキュメントを確認しながらやりました。
Slurm Workload Manager - Containers Guide
設定は大まかに分けると以下となります。
- Container (Rootless)のインストール
- OCI Container bundle
- oci.conf
構成
今回も、ベースは以前までと同じ環境を使っていきます。
- Slurm 22.05.04
- Master + Node1~4
- Master,Node1~4は全てVirtual Box上に作成したRocky linux 8.6
設定作業
以降で環境を準備していきますが、non-rootのコンテナ起動ユーザは「john」を想定します。
Docker (Rootless)
対象: Master 、 Node1~4
全ノードにDockerをインストールして、Rootless起動のセットアップを行います。
Dockerをインストールしてはいますが、役割として重要なポイントは以下になるかと思います。
- Container Runtimeであるrunc インストール
- non-rootでのOCIコンテナ(runc)起動のセットアップ
- OCI Container bundleの作成
Install Docker
Dockerをdnfでインストールします。
# dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo # dnf -y install docker-ce docker-ce-cli containerd
↓インストール時にdocker-ce-rootless-extrasがパッケージに含まれている事を確認しておきます。
========================================================================================================== Package Arch Version Repository Size ========================================================================================================== docker-ce-rootless-extras x86_64 20.10.18-3.el8 docker-ce-stable 4.6 M
Setting Docker Rootless
Rootlessの設定を適用していきます。 基本は以下の手順を参考にします。
Run the Docker daemon as a non-root user (Rootless mode) | Docker Documentation
# dnf install -y fuse-overlayfs # dnf install -y iptables # systemctl disable --now docker.service docker.socket
non-rootでの起動ユーザであるjohnの.bashrcに以下のように追記します。
[john@master ~]$ echo "loginctl enable-linger \$(whoami)" >> ~/.bashrc [john@master ~]$ echo "export XDG_RUNTIME_DIR=/run/user/\$(id -u)" >> ~/.bashrc [john@master ~]$ source ~/.bashrc
dockerd-rootless-setuptool.shを実行します。
[john@master ~]$ dockerd-rootless-setuptool.sh install
最後のstdoutに、以下のように表示されます。
・・・ ・・・ export PATH=/usr/bin:$PATH export DOCKER_HOST=unix:///run/user/1002/docker.sock
→こちらの設定も.bashrcに追記し、シェルに反映させておきます。
[john@master ~]$ echo "loginctl enable-linger \$(whoami)" >> ~/.bashrc [john@master ~]$ echo "export XDG_RUNTIME_DIR=/run/user/\$(id -u)" >> ~/.bashrc [john@master ~]$ source ~/.bashrc
これで、ユーザ権限でdockerdが起動できるようになります。
[john@master ~]$ systemctl --user daemon-reload [john@master ~]$ systemctl --user start docker [john@master ~]$ systemctl --user enable docker
docker infoを確認しておきます。
[john@master ~]$ docker info
以下を確認しておきます。
- Default Runtime: runc
- Security Options: 数行の中に"rootless"が記載
- Docker Root Dir: /home/john/.local/share/docker
dockerd-rootless-setuptool.sh check を実行して、rootless設定を確認します。
[john@master ~]$ dockerd-rootless-setuptool.sh check --force [INFO] Requirements are satisfied
runcが使えることも念の為、確認しておきます。
[john@master ~]$ runc --version runc version 1.1.4 commit: v1.1.4-0-g5fd4c4d spec: 1.0.2-dev go: go1.17.13 libseccomp: 2.5.2
以上です。
ここまでが対象: Master 、 Node1~4での共通部分になります。
Create OCI Container bundle
次にContainer bundleをmasterノード上で作成していきます。(masterが必須という訳ではありません)
前章で、Docker(Rootless)が問題なく設定できていれば、Container bundle作成の為の環境も出来ていることになります。
Container bundleはNFS共有先に格納するつもりなので作業はmasterノードだけで作業します。また、今回のContainer bundleは、Docker imageの「centos:latest」を使って作成してみようと思います。
dockerイメージをpullします。
[john@master john]$ docker pull centos:latest latest: Pulling from library/centos a1d0c7532777: Pull complete Digest: sha256:a27fd8080b517143cbbbab9dfb7c8571c40d67d534bbdee55bd6c473f432b177 Status: Downloaded newer image for centos:latest docker.io/library/centos:latest[john@master john]$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE centos latest 5d0da3dc9764 12 months ago 231MB
次にdocker exportで、Container bundleを作成します。
Container bundleは全計算ノードで必要な為、NFS共有(/mnt/share)に作成しておきます。
今回は「centos_image」という名前にしましたが、名前は任意です。rootfsは名前を変えてはいけません。
[john@master ~]$ cd /mnt/share/john [john@master ~]$ docker create --name centos centos:latest [john@master ~]$ mkdir -p centos_image/rootfs/ [john@master ~]$ docker export centos | tar -C centos_image/rootfs/ -xf - [john@master ~]$ cd centos_image/ [john@master centos_image]$ runc --rootless=true spec --rootless [john@master centos_image]$ cd ..
→最後のcdの一つ手前、runc --rootless=true spec --rootlessでcentos_image/config.jsonが作成されている事も確認しておきます。
[john@master john]$ ls -la centos_image/ total 8 drwxrwxr-x 3 john john 39 Oct 10 05:44 . drwxrwxr-x 3 john john 4096 Oct 10 05:59 .. -rw-rw-r-- 1 john john 2639 Oct 10 05:30 config.json drwxrwxr-x 17 john john 248 Oct 10 05:12 rootfs
では次にContainer bundleからコンテナが起動する事を確認してみます。
Test Container bundle
先ほどの手順で「/mnt/share/john/centos_image」にContainer bundleファイルができました。
コンテナとしての稼働テストをしていきます。 ここからはruncコマンドを使います。
runc runでコンテナのシェルが起動します。
[john@master john]$ runc run --bundle /mnt/share/john/centos_image centos
適当にコマンドを入力すると結果が出力されています。
sh-4.4# grep ^NAME /etc/os-release NAME="CentOS Linux" sh-4.4# exit exit
→Container bundleから作成したコンテナが、無事に動く事が確認できました。
補足.1
上記ではrunc run ~で動作確認しましたが
- runc create ~
- runc start ~
で確認する場合、
- runc createで以下のようなエラーがでるかと思います。
例)runc create centos-test --bundle centos_image/
ERRO[0000] runc create failed: cannot allocate tty if runc will detach without setting console socket
→centos_image/config.jsonのprocess{}.terminalをtrue→falseに変更するとエラーなくcreaterできると思います。
(※ Slurmでもconfig.jsonは読み込んだ後に、処理内でterminalはfalseに変更されていました。)
また、runc startで以下のようにエラーがでるかと思います。
例)runc start centos-test
[john@master john]$ sh: cannot set terminal process group (-1): Inappropriate ioctl for device sh: no job control in this shell
→centos_image/config.jsonのprocess{}.args[]を"sh"→"echo","hello-world"などにしておくと、ここでのエラーは回避できるかと思います。
補足 以上
oci.conf
それではoci.confを作成します。 今回は以下のように作成しました。
ContainerPath=/home/john/local_image CreateEnvFile=False RunTimeQuery="runc --rootless=true --root=/tmp/ state %n.%u.%j.%s.%t" RunTimeKill="runc --rootless=true --root=/tmp/ kill -a %n.%u.%j.%s.%t" RunTimeDelete="runc --rootless=true --root=/tmp/ delete --force %n.%u.%j.%s.%t" RunTimeRun="runc --rootless=true --root=/tmp/ run %n.%u.%j.%s.%t -b %b"
基本的には公式をそのまま拝借しました。 Slurm Workload Manager - oci.conf
RunTimeCreate&RunTimeStartは、RunTimeRunとは一緒には設定できない。などruncコマンドの挙動と関連します。
ContainerPathは、計算ノードの処理内(slurmstepd)で読み込んだbundleを展開する為に使うディレクトリのようです。
計算ノード内で未存在のディレクトリ(/home/john/local_image)を指定しておきました。
↓ContainerPathに実際に前段のbundle作成先の/mnt/share/john/centos_imageを指定すると、sbatch時に計算ノードでエラーが出てしまいます。
[2022-10-08T12:27:45.291] [689.batch] error: \_write_config: unable to open /home/john/centos_image/config.json: File exists [2022-10-08T12:27:45.291] [689.batch] error: setup_container: container setup failed: File exists [2022-10-08T12:27:45.291] [689.batch] error: _step_setup: container setup failed: File exists [2022-10-08T12:27:45.291] error: slurmstepd return code 17: File exists
それでは、oci.confをNode1~4に撒きます(Node1への例)。
scp -p /etc/slurm/oci.conf node1:/etc/slurm
忘れずにslurmd, slurmctldを再起動します。
sudo systemctl restart slurmd
sudo systemctl restart slurmctld
動かしてみる
sbatch --container
それでは実際に動かしてみます。
今回は簡単なサンプルでsbatchをmasterから投げてみます。
[john@master ~]$ sbatch --container /mnt/share/john/centos_image --wrap 'grep ^NAME /etc/os-release' Submitted batch job 779
すぐに処理が終わってsqueueでは視認できなかったので、sacctで履歴を確認してみます。
[slurm@master slurm]$ sacct --alluser --job 779 JobID JobName Partition Account AllocCPUS State ExitCode ------------ ---------- ---------- ---------- ---------- ---------- -------- 779 wrap partition+ chemistry 1 COMPLETED 0:0 779.batch batch chemistry 1 COMPLETED 0:0
→COMPLETEDしているようです。
では、Node1で出力されたログを確認します。
[john@node1 ~]$ cat slurm-779.out NAME="CentOS Linux" slurmstepd: error: _try_parse: JSON parsing error 71 bytes: boolean expected
→grep ^NAME /etc/os-releaseの出力NAME="CentOS Linux"が無事出力されました!!!
...しかし...
その後に slurmstepd: error: _try_parse: JSON parsing error 71 bytes: boolean expected
ちょっと許しがたいですねこれは。。。
→解決したら更新したいと思います。
※解決の時間がしばらくとれないかも知れず、忘れない為に今回はひとまずこの段階で記事にさせていただきました。
補足.2
sbatchを最初に実行した際に、僕の環境で出たエラーです。
[2022-10-07T12:25:40.018] [501.0] debug3: plugin_peek->_verify_syms: found Slurm plugin name:Serializer URL encoded plugin type:serializer/url-encoded version:0x160504 [2022-10-07T12:25:40.018] [501.0] debug3: plugin_peek: dlopen(/usr/local/lib/slurm/serializer_json.so): libjson-c.so.5: cannot open shared object file: No such file or directory
libjson-c.so.5がなかったようでした。
対策をメモしておきます。
json-cをインストールします。Slurm Workload Manager - Download Slurm
\# cd /usr/local \# git clone --depth 1 --single-branch -b json-c-0.15-20200726 https://github.com/json-c/json-c.git json-c \# mkdir json-c-build \# cd json-c-build \# cmake ../json-c \# make \# sudo make install
/usr/local/lib64配下にライブラリが作成(cmake先が微妙でした)
# find / -name ibjson-c.so.5 /usr/local/lib64/libjson-c.so.5
共有ライブラリ参照先に追加しておきます。
# echo "/usr/local/lib64" > /etc/ld.so.conf.d/json-c.conf
\# ldconfig
\# ldconfig -p | grep libjson
libjson-c.so.5 (libc6,x86-64) => /usr/local/lib64/libjson-c.so.5
libjson-c.so.4 (libc6,x86-64) => /lib64/libjson-c.so.4
libjson-c.so (libc6,x86-64) => /usr/local/lib64/libjson-c.so
libjson-c.so (libc6,x86-64) => /lib64/libjson-c.so
補足 以上
さいごに
(未解決) slurmstepd: error: _try_parse: JSON parsing error 71 bytes: boolean expected
エラーは残りますが、--containerオプションでOCI Containerが動く、という所を感じるところまでは来ました笑。
エラーが解決したら記事はアップしたいとおもいます。
2022/11/26 アップ
感想
今後のバージョン(23~)で、DockerやPodmanなどのインターフェイスとSlurm間での連携の直感性が上がると嬉しいですが、 もう少し重たいコンテナワークロードなどを動かして検証してみたい、とは思いました。
Singularityの設定方法もちゃんと見てはいないですが(見ておけよと)色んなHPC運用環境があると思うのでコンテナ最適解を選ぶにも、このあたりが充実していくのは良いことですね。
(あとC言語も勉強しよっと)
Slurm Installその後4. mpi4pyでOpenMPI並列処理
はじめに
これまでの記事ではSlurmの
- アカウンティング設定
- リソース制限(Limit)-> acount/user associationsやQoSでの制限適用
をやってみました。
今回ですが、折角ジョブスケジューラを扱うので並列処理のSlurmでの設定も少し勉強してみたいと思いました。僕の環境の虚弱な計算ノード達ではありますが、並列処理の環境準備をやってみたいと思います。
目次
OpenMPI / mpi4py
並列処理の実行については、SlurmでいくつかのMPIがサポートされています。
MPI Users Guide slurm.schedmd.com
今回はそのうちの一つのOpenMPIを使うことなります。ただ、僕がC/C++/Fortranなどを通っていないので、(まだ親近感が多少ある)pythonを使って、そのバインディングである「mpi4py (MPI for Python)」で並列処理を動かしていきたいと思います。
ちなみにOpenMPIをPythonモジュールで扱えるものは今の所mpi4py一択のようです。今後困る事がなければ、マイLabではmpi4pyを使っていくつもりです。
必要なもの
環境はこれまでと同じで、以下がベースです。
・Slurm 22.05
・Master + Node1~4は全てRocky linux 8.6 (Virtual Box)
まず、今回の並列化環境に追加で必要なものを整理しておきます。
OpenMPI
MPI(Message Passing Interface)は、プロセス並列の為の標準的APIを提供するライブラリを指す。MPIの実装としてOSS利用可能なメジャーなものの一つがOpenMPI。
OpenMPI: https://www.open-mpi.org/
pmi
PMI(Process Management Interface)は元々はMPICHの一部として開発・配布されていたものっぽい。 MPI実装からプロセス管理機能が独立・標準化されたインターフェイスとして提供されるAPIで、リソースマネージャやジョブスケジューラから利用される事を想定している。
大まかなバージョンは
- PMI-1、PMI-2(PMI-1の改良番)、PMIx v1-v4 (xは「Exsascale」の意。またPMI-1,2と下位互換)。v5も開発が進んでいるそう。
(大規模な並列環境で)大量のMPIジョブプロセスを迅速にスケーラブルできる事を主眼に、プロセスの起動サポート、メモリ効率利用、各種MPI実装の分離開発、など可能にする。
参考:
deepdive into PMI(x) : https://container-in-hpc.org/artefacts/isc/2022/hpcw/pdf/5_hpc/3_PMIx-Deep-Dive.pdf
PMIx: Process Management for Exascale Environments : http:// https://dl.acm.org/doi/pdf/10.1145/3127024.3127027
mpi4py
MPI for Python — MPI for Python 3.1.3 documentation
設定1. 並列化
ではこれから実際に設定をやっていきます。
masterとNode1~4の全マシンに対して行います。
OpenMPI / PMI
mpi4pyを利用する為にもまずは、OpenMPIを入れておく必要があります。
またPMIですが、OpenMPIにもPMIはembededされていて、ビルド時に"--with-pmi"、"--with-pmix"オプションをつける事で「PMI」「PMIx」がビルドされるようです。
OpenMPIバージョンごとの対応は以下 Which Environments Include Support for PMIx? | OpenPMIx
SlurmでもPMIを認識させる必要があり(srun --mpi=listで確認)Ver 22.05ではPMIx v2.x、v3.x、v4.x、v5.x をサポートしているようです。PMIx v5は開発中みたいですが...
ただ、SlurmのドキュメントをみるとSlurmインストール時点でPMIxは構築しておく必要があった(?)のか、後からPMIx追加をトライするも出来手こずりそうでした。なので今回はSlurmがデフォルト対応している「PMI-2」を使う事にしたい思います。
memo: 自前でPMIxをビルドする場合は以下やっておく
dnf -y install flex libev libevent-devel hwloc
ただ、SlurmのドキュメントをみるとSlurmインストール時点でPMIxは構築しておく必要があった(?)のか、後からPMIx追加をトライするも出来手こずりそうでした。なので今回はSlurmがデフォルト対応している「PMI-2」を使う事にしたい思います。
memo: 自前でPMIxをビルドする場合は以下やっておく
dnf -y install flex libev libevent-devel hwloc
では、現時点でのOpenMPI最新版を入れてみます。(公式 https://www.open-mpi.org/)
インストール先は/usr/local/openmpiとしておきます。
- cd /usr/local/src && sudo wget https://download.open-mpi.org/release/open-mpi/v4.1/openmpi-4.1.4.tar.gz
- cd /usr/local/src
- sudo tar -xvf openmpi-4.1.4.tar.gz && cd openmpi-4.1.4
- sudo ./configure --with-slurm --with-pmi --prefix="/usr/local/openmpi"
- sudo make && sudo make install
パス、ライブラリパス
PATHとLD_LIBRARY_PATHの設定が必要です。
今後、ユーザを適用に作って増やしたりすると思いますので/etc/profile.d配下にopenmpi.shを作成してユーザ共通にしておきます。
sudo cat <<EOF > /etc/profile.d/openmpi.sh export PATH="\$PATH:/usr/local/openmpi/bin" export LD_LIBRARY_PATH="\$LD_LIBRARY_PATH:/usr/local/openmpi/lib" EOF
mpi4py
(なければ)先にpython3-develを入れておきます。
dnf -y install python3-devel
pipでインストールできます。
$ pip3 install mpi4py
Collecting mpi4py
Downloading https://files.pythonhosted.org/packages/20/50/d358fe2b56075163b75eca30c2faa6455c50b9978dd26f0fc4e3879b1062/mpi4py-3.1.3.tar.gz (2.5MB)
100% |████████████████████████████████| 2.5MB 389kB/s
Installing collected packages: mpi4py
Running setup.py install for mpi4py ... done
Successfully installed mpi4py-3.1.3
→Ver3.1.3が入りました。ひとまずこれでOKとしましょう。
全マシン共通の設定は以上です。
設定2. NFS共有
NFS
続いてですが、折角の機会なのでNFS共有の仕組みを入れます。
(割愛)NFS共有の設定手順は割愛します。
※色んな方がWebに上げてくださっているので、検索して上位Hitしてくるやりかたで問題ないと思います。
僕の環境は/mnt/shareというディレクトリをマスタ(master.science.com)とNode1~4でNFS共有しました。
以下はnode1の例ですが、他のnode2~4でも同様に見える状態です。
[john@node1 ~]$ df -Th | grep nfs master.science.com:/mnt/share nfs4 70G 6.3G 64G 9% /mnt/share
サンプル並列処理
mpi4pyをインポートして標準出力を行う、だけのサンプルです。
NFS共有ディレクトリを利用して/mnt/share/[user]/mpitest.pyと配置しておきます。
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
name = MPI.Get_processor_name()
print(f"Hello, world! from rank {rank} out of {size} on {name}")
補足
- MPIプログラムで生成される各プロセスは一意な値が設定され、
get_rank()メソッドで取得できる - コミュニケータ(通信を実施するためのプロセスのグループ)のサイズは
get_size()メソッドで取得できる - 生成されるプロセスの名前が
Get_processor_name()メソッドで取得できる
設定3. slurm.conf
/etc/slurm/slurm.conf
以下のようにデフォルトを変更しておきます。 noneのままでもコマンドラインのオプションで--mpi=pmi2と毎回入力して実行もできます。
#MpiDefault=none MpiDefault=pmi2
.confを変更したので以下も実施しておきます。
/etc/slurm/slurm.confをnode1~4に配布してslurmdを再起動masterもslurmctldを再起動
設定はこれで以上です。
では、サンプルの並列処理を動かしていきたいと思います。
動かしてみる
では動かして行きます。前回から引き続きjohnユーザを使います。
今まではずっとsbatchでしたが、今回はインタラクティブに動かしてみようと思います。
- salloc
- srun
salloc
Slurmのマシンリソースの割当を要求します。
johnユーザでnode1から実行します。ノードへの計算負荷は全くない状況です。
確認しておくと/etc/slurm/slurm.confは以下の設定です。
PartitionName=partition1 Nodes=node[1-2] Default=YES MaxTime=INFINITE State=UP PartitionName=partition2 Nodes=node[3-4] Default=YES MaxTime=INFINITE State=UP
リソースは--nodes=2で2ノードの割当を要求してみます。
[john@node1 ~]$ salloc --nodes=2 bash salloc: Granted job allocation 376 [john@node1 ~]$
→Granted job allocation 376と、無事リソースが割当てられたようです。 (--ptyをオプションにつけると割当されたノードのリモートホスト上で、対話側シェルが起動された状態になります)
この段階でsqueueを確認してみます。
[john@master john]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
376 partition interact john R 0:11 2 node[3-4]
→Node3、4が割り当てられている事がわかります。NAMEは指定しなければ"interact"と表示されるようです。
それではsrunを実行してみます。
※/mnt/shareNFS共有ディレクトリで実行しているので、mpitest.pyを各Nodeへ配布する必要はありません。
するとsrun python3 /mnt/share/john/mpitest.pyを実行した所で、
ImportError: libmpi.so.12: cannot open shared object file: No such file or directory srun: error: node3: tasks 0-1: Exited with exit code 1
libmpi.so.12がないと言われます。mpi4pyでは「libmpi.so.12」としてOpenMPIのライブラリが参照されるようで、
- cd /usr/local/openmpi/lib
- sudo ln -s libmpi.so.40.30.4 libmpi.so.12
でopenmpi4.1.4のライブラリを参照できるようにしました。
(ちなみにOpenMPIを1.10.2のバージョンでやると上記エラーは発生しませんでした)
それでは気を取り直してsrunを再度行います。
[john@node1 ~]$ srun python3 /mnt/share/john/mpitest.py Hello, world! from rank 0 out of 2 on node3 Hello, world! from rank 1 out of 2 on node4
→2ノード(Node3,4)で並列がそれぞれ実行されました。コミュニケーター内のプロセス総数(=2)で、各プロセスが一意に割当られていそう(rank=0,1)ですね。上手く動いていそうです。
ひとまずexitします。
[john@node1 ~]$ exit exit salloc: Relinquishing job allocation 376 salloc: Job allocation 376 has been revoked. [john@node1 ~]$
exitしたタイミングでsqueueをたたくと、割当解除が確認できます。
[john@master john]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
試しに先ほどより1台ノードを欲張って、--nodes=3で3ノードを要求してみると...
[john@node1 ~]$ salloc --nodes=3 bash salloc: Requested partition configuration not available now salloc: Pending job allocation 377 salloc: job 377 queued and waiting for resources
[john@master john]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
377 partition interact john PD 0:00 3 (PartitionNodeLimit)
→リソース割当可能なPartitionが存在しない場合は、PartitionNodeLimitで保留(PD)されてしまうようです。ctrl+zでキャンセルしておきます。
念の為、partitionの設定を変えて挙動の変化があるか?見てみます。
4ノードを全て同じpartition(partition_all)と変更してみました。
[slurm@master ~]$ sinfo PARTITION AVAIL TIMELIMIT NODES STATE NODELIST partition_all* up infinite 4 idle node[1-4]
sallocで--nodes=4を要求してみると、
[john@node1 ~]$ salloc --nodes=4 bash salloc: Granted job allocation 408
→partitionを変更してノードを増やしているので(2→4),、ちゃんと--nodes=4で割当てされましたね。さきほどは2を超えるとpartitionのリソースを超えて保留されました。
squeueでも割当が確認できます(node[1-4])
[john@master john]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
408 partition interact john R 0:12 4 node[1-4]
では、srunでmpitest.pyを実行します。
[john@node1 ~]$ srun python3 /mnt/share/john/mpitest.py Hello, world! from rank 0 out of 4 on node1 Hello, world! from rank 2 out of 4 on node3 Hello, world! from rank 3 out of 4 on node4 Hello, world! from rank 1 out of 4 on node2
→4ノード(Node1~4)に対して、4並列で問題なく動いていそうです。
今回は以上になります。
最後に
今回は、
- mpi4run(OpenMPI)を使った並列処理の設定
- 動作確認(salloc, srun)、partition設定を変えてみる
をやってみました。
今回は手動でsallocなどをやりましたが実運用だと、ノードの数や種類、ジョブのワークロードも様々です。そのあたりをSlurmがいい感じにスケジューリングしてくれると考えると、少しワクワクしてきますね。
Slurm Installその後3.リソース制限 QoS
はじめに
前回の続きで、Slurmのリソース制限の方法をやっていこうと思います。
目次
前回
前回はassociationを用いて以下のような制限をやってみました。
associationを用いた制限
・ userレベル
・ accountレベル
・ account同士の親子(Parent/Child)関係で制限適用
・ userレベル
・ accountレベル
・ account同士の親子(Parent/Child)関係で制限適用
今回
association以外の制限の方法として「QoS」という機能がSlurmにはあります。 今回はこちらをみていきます。
QoSとは?
Quality of Serviceの略。
Quality of Service - Wikipedia
「引用」『フリー百科事典 ウィキペディア日本語版』より。 2022年4月25日 (月) 02:22 UTC
URL:Quality of Service - Wikipedia
このあたりは門外漢なのですが、もともとはコンピュータ・ネットワークの世界から標準的なワードとして広まったんでしょうか??限られたコンピューティング・リソースを差別/優先して(サービス品質)、効率・安定的に利用者に供給する仕組みのようです。
世の中のたくさんの人々がコンピューティング・リソースを消費しあう訳なので、このような考え方が必要な事はなんとなく理解できますね。
↓一例ですが、ネットワーク以外にもQoSは色んな所で登場するようです。
- 仮想ストレージ → IOや転送レートなど性能レベル制御
- Kuberneters → Podの利用リソース制御、QoS Class
SlurmにおけるQoS
公式 Slurm Workload Manager - Quality of Service (QOS)
さきほど述べたQoSと似た概念として捉えておおむね問題なさそうです。Slurmで扱う制限をQoSとして指定することでジョブの実行リソースを制限していく仕組みのようです。
また「制限」の話から文脈は逸れますが、Slurmのジョブスケジューリング「優先付け(priority)」においてもQoSは優先順決定要因の中の一つとして登場するようです。 (こちらについてはまた勉強したら)
QoSの設定について
QoSは、Slurmで制限できる項目を「セット」にして作成する事ができます。
作成したQoSは以下に対して指定する事が出来ます。
partition
job (sbatch / salloc / srun、を実行時に--qos=で指定)
association (user / account / root)
リソース制限指定の優先
Slurmのリソース制限の適用には、適用の優先順があらかじめ決まっていて、次の1から順番に優先されていきます。
Slurm Workload Manager - Resource Limits
- Partition QOS limit
- Job QOS limit
- User association
- Account association(s), ascending the hierarchy
- Root/Cluster association
- Partition limit
- None
前回の記事(https://taqqu.hatenablog.com/entry/2022/09/10/174507)では、この優先順でいうところの3(User association)と4(Account association(s))を既に設定したことになります。
※ちなみに「Jobの実行時にオプションで'OverPartQOS' フラグをつけてPartition QoSと優先順位を逆転させる」ような事も可能だとか。
QoS設定をやってみる
では、実際にQoSを設定していきたいと思います。
前回まではassociationに対して、sacctmgr modify account/user <name> set <limits>にように直接制限を付与する事をやりました。
前回の制限内容
[slurm@master ~]$ sacctmgr show associations format=account,user,GrpJobs,GrpSubmitJobs
Account User GrpJobs GrpSubmit
---------- ---------- ------- ---------
root
root root
root slurm
chemistry 1 2
chemistry john
chemistry+
chemistry+ tom
- account -> "chemistry" にたいしてGrpJobs=1, GrpSubmit=2を設定
[slurm@master ~]$ sacctmgr show association format=account,Parentname
Account ParentName
---------- ----------
root
root
root
chemistry root
chemistry
chemistry+ chemistry
chemistry+
でした。
今回は、QoSを新規作成してみてから、これら(前回作成済)の制限とで、適用優先関係も簡単にみていければと思います。
今回の制限内容
具体的にはですが、前回作成したassociation(account)の制限より優先が高くなるか?をみたいので、以下の順番でみていきたいと思います。
QoSをまず作成してから、
イメージ
イメージの黄色塗り部分がQoSです。順に作成して、挙動をみていきます。

QoS設定前の動作確認
QoS作成前の動作をみておきましょう。前回記事の最後のsubmitのおさらいになります。
john( account : chemisty)で実行
[john@node1 ~]$ sbatch test.sh Submitted batch job 131 [john@node1 ~]$ sbatch test.sh Submitted batch job 132 [john@node1 ~]$ sbatch test.sh sbatch: error: AssocGrpSubmitJobsLimit sbatch: error: Batch job submission failed: Job violates accounting/QOS policy (job submit limit, user's size and/or time limits)
→3回目の実行でerrorになります。GrpSubmitJobs=2が効いてsubmit(sbatch実行)が3回目でエラー
squeueで確認
[slurm@master ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
132 partition test john PD 0:00 1 (AssocGrpJobsLimit)
131 partition test john R 0:08 1 node3
→2回目の実行(ID=132)はSubmitはされたものの、GrpJobs=1が効いて保留(ST=PD)になっている事がわかります。
はい、という事でこれからQoSを設定して挙動の変化をみていきます。
QoS設定
それではQoSを設定していきます。
slurm.confファイル
まずは/etc/slurm/slurm.confを確認すると(前回続きから)現状はlimitsになっています。
AccountingStorageEnforce=limits
ここで再度AccountingStorageEnforceについて確認しておきます。
| 設定例 | 内容 |
|---|---|
| associations | associaionsがデータベース(slurmdbd)に登録されていない場合、ユーザーはジョブ実行できない。associations登録がない=ユーザーは無効なアカウント扱い。 |
| qos | すべてのジョブが有効な QoS (Quality of Service) を指定することが、デフォルトで明示的に要求される。QoS値はデータベース内の各associationsに対して定義されます。このオプションを設定すると'associations'オプションが自動的に設定。QoSで制限を実施したい場合は、'limits' オプションを使用する必要があります。 |
| limits | associationsに設定された制限が強制される。このオプションを設定すると、'associations' オプションも設定されます。 |
| nojobs | ジョブ情報をDB保存しない場合に設定 |
| nosteps | ジョブステップ情報をDB保存しない場合に設定 |
※全部ではありません。他にも,safe,wckeys...といった設定値があります
→limitsのままだとQoSは制限されてしまいますので、qosを追加しておきます。(slurm.confの再配布とslurmctld、slurmdの再起動も忘れずに)
#AccountingStorageEnforce=0 #AccountingStorageEnforce=associations #AccountingStorageEnforce=limits AccountingStorageEnforce=limits,qos
QoSの作成 (job)
次にQoSの作成です。これまでも出てきたsacctmgrコマンドを使います。
まずはJob QoSとして、以下の通り作成します。名前「job_qos」は適当です。
[slurm@master ~]$ sacctmgr add qos job_qos Adding QOS(s) job_qos Settings Description = job_qos Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
次に、イメージに書いたように、QoS「job_qos」に対してGrpJobs=2, GrpSubmitJobs=3を設定します。 (associationsの制限時からjob、submitそれぞれ上限数を+1)
[slurm@master ~]$ sacctmgr modify qos job_qos set GrpJobs=2 GrpSubmitJobs=3 Modified qos... job_qos Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
結果を確認してみます。
[slurm@master ~]$ sacctmgr show qos format=name,GrpJobs,GrpSubmitjobs
Name GrpJobs GrpSubmit
---------- ------- ---------
normal
job_qos 2 3
設定できていそうですね。
動かしてみる
Job QoS
それではさきほど作成した制限(QoS)で「GrpJobs,GrpSubmitjobs」これまでの制限(associations)より優先されるか見ていきましょう。
submit数と実行数がそれぞれ1づつ増えていればOKという事になります。
Jobの実行時に(submit)でQoSを指定しますので、sbatchにオプション--qos=job_qosをつけて実行します。
[john@node1 ~]$ sbatch --qos=job_qos test.sh sbatch: error: Batch job submission failed: Invalid qos specification
Invalid qos specificationとエラーになりました。
このままだとどうやらjohnがQos(job_qos)を利用できないようで、以下のように所属するaccount/associationの"chemistry"にQosをセットする必要がありました。
[slurm@master ~]$ sacctmgr modify account chemistry set qos=job_qos Modified account associations... C = sample-cluster A = chemistry of root C = sample-cluster A = chemistry_japan U = tom C = sample-cluster A = chemistry U = john Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
※ 以下のようにjohn(user/association)にQoSを設定する方法でも大丈夫でした。
sacctmgr modify user john set qos=job_qos
どちらに設定するのかは管理ポリシーに依るところかも知れません。
では気を取り直して、再度実行(submit)します。
[john@node1 ~]$ sbatch --qos=job_qos test.sh Submitted batch job 254 [john@node1 ~]$ sbatch --qos=job_qos test.sh Submitted batch job 255 [john@node1 ~]$ sbatch --qos=job_qos test.sh Submitted batch job 256 [john@node1 ~]$ sbatch --qos=job_qos test.sh sbatch: error: QOSGrpSubmitJobsLimit sbatch: error: Batch job submission failed: Job violates accounting/QOS policy (job submit limit, user's size and/or time limits)
→4回目の実行でerrorになります。GrpSubmitJobs=3が効いてsubmit(sbatch実行)が4回目でエラーです。QoS設定前より上限が+1され、出力の"QOSGrpSubmitJobsLimit"のメッセージからも今回設定したQoSが優先されている事がわかります。
squeueで確認
[slurm@master ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
256 partition test john PD 0:00 1 (QOSGrpJobsLimit)
254 partition test john R 0:10 1 node3
255 partition test john R 0:10 1 node3
→こちらも2回目の実行までRUNしました(ID=255)。QoS設定前より上限が+1されたGrpJobs=2が効いて3回目の実行(ID=256)は保留になっている事がわかります。
Job QoSがaccount/associationでの制限より優先された事がわかりました。
補足ですが、一応ユーザtomでも実行しておきます。
[tom@node1 ~]$ sbatch --qos=job_qos test.sh Submitted batch job 260 [tom@node1 ~]$ sbatch --qos=job_qos test.sh Submitted batch job 261 [tom@node1 ~]$ sbatch --qos=job_qos test.sh Submitted batch job 262 [tom@node1 ~]$ sbatch --qos=job_qos test.sh sbatch: error: QOSGrpSubmitJobsLimit sbatch: error: Batch job submission failed: Job violates accounting/QOS policy (job submit limit, user's size and/or time limits)
→GrpSubmitJobs=3が効いていますね。Child accountでも同様にQoSが適用されているようです。squeueは割愛します。
では次にこのJob QoSよりpartition QOSが優先されるか?を見ていきます。
QoS設定
ではPartition QoSを設定していきます。 GrpSubmitJobs=0だけを設定して、Partitionでジョブが実行できないようにするイメージです。
QoSの作成(partition)
先程と同じやりかたで、sacctmgrコマンドでQoSを作成していきます。「part_qos」
[slurm@master ~]$ sacctmgr add qos part_qos Adding QOS(s) part_qos Settings Description = part_qos Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
さらに、イメージに書いたようにQoS「part_qos」に対してGrpSubmitJobs=0を設定します。(submitできなくする)
[slurm@master ~]$ sacctmgr modify qos part_qos set GrpSubmitJobs=0 Modified qos... part_qos Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
結果を確認してみます。
[slurm@master ~]$ sacctmgr show qos format=name,GrpJobs,GrpSubmitjobs
Name GrpJobs GrpSubmit
---------- ------- ---------
normal
job_qos 2 3
part_qos 0
PartitionへのQoS設定
partitionにQoSを設定したい場合は、/etc/slurm/slurm.confに直接記載する事ができます。
今回のjobはpartition2を使うようにしているので、slurm.confのpartition2の定義にQos=part_qosを追加します。(slurm.confの再配布とslurmctld、slurmdの再起動も忘れずに)
PartitionName=partition2 Nodes=node[3-4] Default=YES MaxTime=INFINITE State=UP Qos=part_qos
動かしてみる
Partition QoS
では、Jobを実行します。
[john@node1 ~]$ sbatch test.sh sbatch: error: QOSGrpSubmitJobsLimit sbatch: error: Batch job submission failed: Job violates accounting/QOS policy (job submit limit, user's size and/or time limits)
→先ほどまでは3回までsubmitできましたが、1回目から実行エラーがでます。GrpSubmitJobs=0がちゃんと効いていますね。
squeueで確認
[slurm@master ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
→submitできないので当然の結果ですね。
そしてPartition QoSの場合は、user/account/associationに対してQoSをセットする必要も無かったようです。
という事で、Partition QoSはとてもシンプルにやってしまいましたが、Job QoSよりpartition QOSが優先される事が確認できました。
最後に
今回は、
をやってみました。
Slurmの制限は、今回使用した「GrpJobs」「GrpSubmitJobs」のような制限項目の単位でpriority制御されるようです。
詳細 - Slurm Workload Manager - Resource Limits
ですので、
制限したい項目が↑のどれに当てはまるかも確認した上で、階層的な制御方法をデザインしていく必要があるのかも知れません(Slurmクラスタを自組織で柔軟に運用したい場合)。
今回は以上です。
Slurm Installその後2.リソース制限 associations
はじめに
今回は、前回記事で作成したassociations設定に対してSlurmのリソースを掛ける設定をやってみます。
- はじめに
- リソース制限 設定無しの状態
- 動かしてみる(1)
- userレベルassociationsのリソース制限
- 動かしてみる(2)
- accountレベルassociationsのリソース制限
- 制限の設定
- 動かしてみる(3)
- 最後に
前回の流れ
おさらい
1. アカウント管理無効状態→johnユーザでsbatch実行 →実行OK
2. アカウント管理有効化→johnユーザでsbatch実行→不可(Deny)
3. associationsを作成
cluster: 「sample-cluster」
account: 「Chemistry」
user: 「 john」
4. johnユーザでsbatch実行 → 再び実行OK
2. アカウント管理有効化→johnユーザでsbatch実行→不可(Deny)
3. associationsを作成
cluster: 「sample-cluster」
account: 「Chemistry」
user: 「 john」
4. johnユーザでsbatch実行 → 再び実行OK
前回記事はこちら taqqu.hatenablog.com
associationsの状態
sacctmgrコマンドでassociationsレコードを確認しておきます。
[slurm@master ~]$ sacctmgr show assoc format=cluster,account,user Cluster Account User ---------- ---------- ---------- sample-cl+ root sample-cl+ root root sample-cl+ chemistry sample-cl+ chemistry john
→defaultである「root」と検証ユーザである「john」のassociationsのレコードが存在しています。
それぞれ
- accountレベル
- userレベル
のレコードが生成された状態でした。
リソース制限 設定無しの状態
ユーザレベルでのassociationを使ったリソースを制限をやっていく前にまず、johnユーザでリソース制限設定の無い状態でsbatchの実行結果を確認しておきます。 環境は前回と同じです。
- node1~4が計算ノード
- partition1(node1, node2), partition2(node3, node4)に構成
- 実行スクリプトとして適当に作成した
test.shをjohnが実行(test.shは中でtest-py-sort.pyを起動する) test.shではparitition2(node3, node4)を使う
動かしてみる(1)
では、連続でジョブを5回ほど実行してみます。
[john@node1 ~]$ sbatch test.sh Submitted batch job 62 [john@node1 ~]$ sbatch test.sh Submitted batch job 63 [john@node1 ~]$ sbatch test.sh Submitted batch job 64 [john@node1 ~]$ sbatch test.sh Submitted batch job 65 [john@node1 ~]$ sbatch test.sh Submitted batch job 66
squeueで確認
[slurm@master ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
66 partition test john PD 0:00 1 (Resources)
62 partition test john R 0:10 1 node3
63 partition test john R 0:10 1 node3
64 partition test john R 0:10 1 node4
65 partition test john R 0:10 1 node4
→partition2(node3&4)で1nodeにつき2ジョブづつ実行(ST=R)。また5番目(ID=66)のジョブはマシンリソースの影響でPD(保留)になっています。前回記事で前半に試した事と同じです。
userレベルassociationsのリソース制限
ではuserレベルassociationsのリソース制限設定をみていきます。 対象のassociationsは以下のレコードです。
* associatons(cluster-> account -> user)
Cluster Account User ---------- ---------- ---------- sample-cl+ chemistry john
上記に対してリソース制限を付与していきます。付与にはsacctmgrを用います。
制限項目
Slurmに組み込まれているassociationに付与可能な制限項目を確認した所、 どうやら項目は以下のように大別されています。
- associationだけ固有に設定できる
- associationまたはQoSのどちらにでも設定できる
※QoSは今回もやりません
Ver22.05時点の項目は以下の通りでした。
associationだけ固有に設定できるポリシー
- Fairshare=
- MaxJobs=
- MaxJobsAccrue=
- MaxSubmitJobs=
- QOS=
associationsにもQoSにも設定可能な制限
- GrpTRESMins=
- GrpTRESRunMins=
- GrpTRES=
- GrpJobs=
- GrpJobsAccrue=
- GrpSubmitJobs=
- GrpWall=
- MaxTRESMinsPerJob=
- MaxTRESPerJob=
- MaxTRESPerNode=
- MaxWallDurationPerJob=
- MinPrioThreshold= *
数が多いので各制限の内容については触れませんが、興味のある方はドキュメントを参照お願いします。
Slurm Workload Manager - Resource Limits
また、「Grp~」始まりの制限設定は、ユーザレベルではなくアカウントレベルの制限で見ていきたいと思います。 ひとまずは、ぱっと見で内容が想像しやすい制限を扱っていきたいと思います。
MaxJobs=
MaxSubmitJobs=
制限の設定
ではsacctmgr modifyでMaxJobs=1、MaxSubmitJobs=2 をjohnのassociationsに設定していきます。
sacctmgr modify user john set MaxJobs=1, MaxSubmitJobs=2
[slurm@master ~]$ sacctmgr modify user john set MaxJobs=1, MaxSubmitJobs=2 Modified user associations... C = sample-cluster A = chemistry U = john Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
→結果を確認してみます。
sacctmgr show associations name=john format=account,user,MaxJobs,MaxSubmitJobs
[slurm@master ~]$ sacctmgr show associations format=account,user,MaxJobs,MaxSubmitJobs
Account User MaxJobs MaxSubmit
---------- ---------- ------- ---------
root
root root
chemistry
chemistry john 1 2
→設定できていそうです。
/etc/slurm/slurm.confの変更
上記に加えてもう1点、slurm.confの修正も必要となります。AccountingStorageEnforceパラメータが前回記事の続きで「associations」(以下)の設定になっています。
#AccountingStorageEnforce=0 AccountingStorageEnforce=associations
以下は前回記事の再掲ですが、設定例を確認するとassociationsのままでは制限は有効化されません。
| 設定例 | 内容 |
|---|---|
| associations | associaionsがデータベース(slurmdbd)に登録されていない場合、ユーザーはジョブ実行できない。associations登録がない=ユーザーは無効なアカウント扱い。 |
| qos | すべてのジョブが有効な qos (Quality of Service) を指定することが、デフォルトで明示的に要求される。QoS値はデータベース内の各associationsに対して定義されます。このオプションを設定すると'associations'オプションが自動的に設定。QOSの制限を実施したい場合は、'limits' オプションを使用する必要があります。※QoSは後日(できれば) |
| limits | associationsとqosに設定された制限が適用される。このオプションを設定すると「associations」オプションが自動的に設定。 |
| nojobs | ジョブ情報をDB保存しない場合に設定 |
| nosteps | ジョブステップ情報をDB保存しない場合に設定 |
※他にも,safe,wckeys...といった設定値が可能
制限を有効化するためにAccountingStorageEnforceパラメータをassociations→limitsに変更します。
#AccountingStorageEnforce=0 #AccountingStorageEnforce=associations AccountingStorageEnforce=limits
以下も実施しておきます。
/etc/slurm/slurm.confをnode1~4に配布してslurmdを再起動masterもslurmctldを再起動
動かしてみる(2)
それではjohnユーザで[動かしてみる(1)]と同様にsbatchを何度か実行して、制限が有効化されているか確認してみたいと思います。
[john@node1 ~]$ sbatch test.sh Submitted batch job 102 [john@node1 ~]$ sbatch test.sh Submitted batch job 103 [john@node1 ~]$ sbatch test.sh sbatch: error: AssocMaxSubmitJobLimit sbatch: error: Batch job submission failed: Job violates accounting/QOS policy (job submit limit, user's size and/or time limits)
→3回目の実行でerrorになります。MaxSubmitJobs=2が効いてsubmit(sbatch実行)が3回目からエラーになっている事がわかります。
squeueで確認
[vagrant@master ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
103 partition test john PD 0:00 1 (AssocMaxJobsLimit)
102 partition test john R 0:08 1 node3
→1回目の実行がRUNしています(ID=102)。2回目の実行(ID=103)は、SubmitはされたもののMaxJobs=1が効いて保留(ST=PD)になっている事がわかります。
シンプルな例ですが、
- userレベルassociationsでのリソース制限
ができました。次にアカウントレベルassociationsによる制限を見てみたいと思います。
accountレベルassociationsのリソース制限
制限項目
設定可能な制限項目は、ユーザレベルassociationsの章で書いた内容と同じです。 ただアカウントレベルでは、*Grp~**始まりの項目を設定みたいと思います。
GrpJobs=
GrpSubmitJobs=
*Grp~**始まりの項目は、前回記事にて触れた親子関係のassociationsにも適用できる制限のようですので、実際にやってみたいと思います。
↓公式からの引用
GrpJobs= The total number of jobs able to run at any given time from an association and its children QOS. If this limit is reached new jobs will be queued but only allowed to run after previous jobs complete from this group.
GrpSubmitJobs= The total number of jobs able to be submitted to the system at any given time from an association and its children or QOS. If this limit is reached new submission requests will be denied until previous jobs complete from this group.
associations(Child)の追加
それでは、既存(親: Parent)のaccount(Chemistry)に対して、子(Child)のaccount(Chemstry Japan)という形でassociationsを作成し、Tomというユーザも新規作成します。 以下のようなイメージです。

はじめにTomユーザを作成しておきます。(master & nodex4)
useradd -u 2001 tom
associationsの追加( account )
次にaccount associationsを作成します。 accountは"chemistry_japan"で、Parent=に"chemisty"を指定します。
sacctmgr add account chemistry_japan Cluster=sample-cluster Description="Chemisty dept. Japan-division" Organization=science.com Parent="chemistry"
[slurm@master ~]$ sacctmgr add account chemistry_japan Cluster=sample-cluster Description="Chemisty dept. Japan-division" Organization=science.com Parent="chemistry" Adding Account(s) chemistry_japan Settings Description = chemisty dept. japan-division Organization = science.com Associations A = chemistry_ C = sample-clu Settings Parent = chemistry Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
associationsの追加( user )
続いて、TomのUser associationsを作成します。
sacctmgr add user tom Cluster=sample-cluster Account=chemistry_japan DefaultAccount=chemistry_japan
[slurm@master ~]$ sacctmgr add user tom Cluster=sample-cluster Account=chemistry_japan DefaultAccount=chemistry_japan Associations = U = tom A = chemistry_ C = sample-clu Non Default Settings Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
→これでchild accountとuserの設定はできました。
制限の設定
まず、さきほどJohnのassociationsに付与したMaxJobs,MaxSubmitJobsは一旦削除しておきます。 -1を指定することで、以前の制限を削除する事ができます。
sacctmgr modify user john set MaxJobs=-1 MaxSubmitJobs=-1
[slurm@master ~]$ sacctmgr modify user john set MaxJobs=-1 MaxSubmitJobs=-1 Modified user associations... C = sample-cluster A = chemistry U = john Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
→前回付与した制限が削除できました。
次にparent account側(chemistry)に制限GrpJobs, GrpSubmitJobsを追加してみたいと思います。
sacctmgr modify account chemistry set GrpJobs=1, GrpSubmitJobs=2
[slurm@master ~]$ sacctmgr modify account chemistry set GrpJobs=1, GrpSubmitJobs=2 Modified account associations... C = sample-cluster A = chemistry of root Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
→これで設定完了です。
では設定の最後に、現状確認してみます。
[slurm@master ~]$ sacctmgr show associations format=account,user,GrpJobs,GrpSubmitJobs
Account User GrpJobs GrpSubmit
---------- ---------- ------- ---------
root
root root
chemistry 1 2
chemistry john
chemistry+
chemistry+ tom
→parent account(chemistry)に「GrpJobs=1, GrpSubmitJobs=2」が、child account(chemisty_japan)には何も設定されていない事がわかります。これで設定は完了です。
動かしてみる(3)
account (parent: chemistry)
まずは動かしてみる(2)と同じ方法で、johnユーザで「GrpJobs、GrpSubmitJobs」が効いているか確認してみます。
[john@node1 ~]$ sbatch test.sh Submitted batch job 106 [john@node1 ~]$ sbatch test.sh Submitted batch job 107 [john@node1 ~]$ sbatch test.sh sbatch: error: AssocGrpSubmitJobsLimit sbatch: error: Batch job submission failed: Job violates accounting/QOS policy (job submit limit, user's size and/or time limits)
→3回目の実行でerrorになります。GrpSubmitJobs=2が効いてsubmit(sbatch実行)が3回目からエラーになっている事がわかります。 MaxSubmitJobsと同じ挙動ですが、accountレベルの制限でもきちんと制限が掛かっています。
[slurm@master ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
107 partition test john PD 0:00 1 (AssocGrpJobsLimit)
106 partition test john R 0:08 1 node3
→こちらも1回目の実行がRUNし(ID=106)、2回目の実行(ID=107)はSubmitはされたものの、GrpJobs=1が効いて保留(ST=PD)になっている事がわかります。
account (child: chemistry_japan)
それでは、子account (chemistry_japan)のTomユーザでsbatchを実行してみます。 (Node1から実行。sbatchのスクリプト内容はjohnと全く同じ)
[tom@node1 ~]$ sbatch test.sh Submitted batch job 108 [tom@node1 ~]$ sbatch test.sh Submitted batch job 109 [tom@node1 ~]$ sbatch test.sh sbatch: error: AssocGrpSubmitJobsLimit sbatch: error: Batch job submission failed: Job violates accounting/QOS policy (job submit limit, user's size and/or time limits) [tom@node1 ~]$
→johnと同様、3回目でGrpSubmitJobs"2"の制限によりerrorになりました。
[vagrant@master ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
109 partition test tom PD 0:00 1 (AssocGrpJobsLimit)
108 partition test tom R 0:07 1 node3
→squeueの方もjohnと同様です。1回目の実行がRUNし(ID=108)、2回目の実行(ID=109)はGrpJobs=1が効いて保留(ST=PD)。
という事で、
- accountレベルassociationsでのリソース制限
- parentとなるaccountのリソース制限がchild accountにも適用される
を確認する事ができました。今回は以上です。
補足
GrpJobs/GrpSubmitJobsですが、userレベルのassociations(john)にも設定はできました。そしてjohnユーザで制限が掛かることも動作確認できましたが、childアカウント所属userであるtomでは制限が掛かりませんでした。 ちゃんとaccountレベルで制限付与しておかなければ、親子設定したchild accountの所属userへは制限が適用されないようです。
最後に
今回は、userレベルとaccountレベルのassociationsに対して、リソース制限機能を付与できる事を試してみました。
Slurmのリソース制限の階層の話には今回も触れる事ができませんでしたが、(できれば)次回はQoS設定をテーマにこちらにも触れられたらと思います。
Slurm Installその後1.アカウンティング
はじめに
「Slurmをいい感じに使えるようにして♪」
※Slurm ・・・ HPC向けOSSジョブスケジューラ
少し前から↑な感じのことを言われてコツコツやっています。とりあえず構築してsbatchは動かせるけど、ジョブスケジューラ運用はやった事ないし「この後どうしていけば良いの?」...の状態でSlurmはよく理解出来ていないことが沢山です。(すくなくとも僕は)
これから、Slurmについてドキュメントやハンズオン(自前環境)で調べたことなど、情報整理がてらに残していきたいと思います。(例えば以下)
- Slurmで管理するアカウントやジョブ・リソース制限
- 「associations」や「QoS」といったキーワードや関連する諸々の設定
Slurm 公式はこちら slurm.schedmd.com
ちなみに
- オンプレ環境
- AWS(Parallel Cluster)今の所は触れません
目次
目的
Slurmのインストールが終わった状態からはじめます。ベストプラクティス的なものはわかりませんが、今回はまず「Slurmでのアカウント管理」としてassociationsの設定をみていきたいと思います。
シンプルかつ徐々に整理していきたいのでリソース制限は今回やりません(できれば次回以降)。
環境
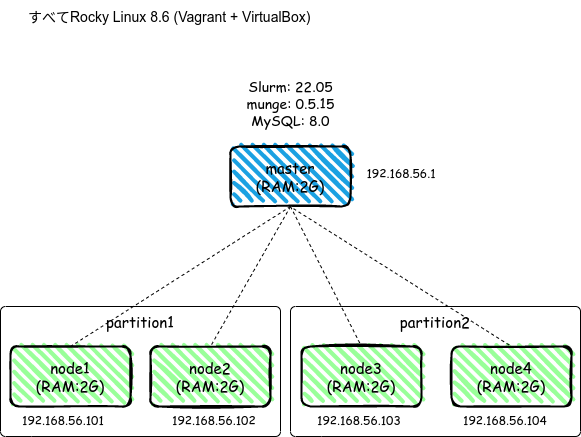
今回のハンズオン勉強用環境は先にざっくりまとめると
です。
SlurmCTLD/SlurmD
- Slurmのマスタ(slurmctld)・ノード(slurmd)は構築済みの前提
- 自宅マシン(Ubuntu22.04LTS)内でSlurm(master/node)はすべてVirtualBox
- GPU設定なし
- masterもnodeもすべてRocky Linux 8.6
- クラスタ名はsample-cluster
- node1~4を計算ノードとし、それぞれpartition1,2に分けるよう配置
※構成は今のところ意識する必要なし
SlurmDBD
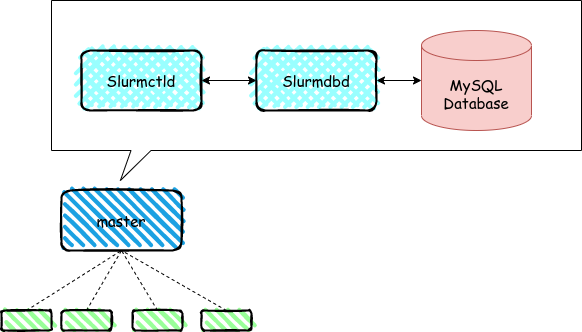
管理ノード(master)には以下も。
Slurmはジョブスケジューリング機能だけでなくアカウント管理やそれに関連付けたジョブ・リソースの制限を行う仕組みも内部に持っています。利用する為にはSlurmDBD/DB(MySQL)を準備しておく事が必要です。
ジョブ・ジョブステップの実行時の情報などもDBに記録されるようになります。※ジョブ・ジョブステップの実行情報はフラットなテキストファイルに記録可能で、SlurmDBDの構成は必須ではありません
今回はSlurmDBDを使って、Slurm内でユーザとアカウント間の「関連付け」の設定を理解していきたいと思います。
下の図はとてもざっくりですが、masterノード内のdaemonとMySQLは以下のように関連するイメージです。
動かしてみる(1)
素のインストール段階では、Slurmのアカウント機能は無効です。この状態でジョブ実行(sbatch)したときの動作を一度確認してみます。
Slurmのジョブ実行(sbatch)はOSアカウントがあれば、実行可能です。
準備
動かす前になんですが、以下3つを先にやっていきたいと思います。
- 設定ファイル確認
- Job実行用のユーザ作成
- Jobスクリプトの準備
設定ファイル確認
/etc/slurm/slurmdbd.conf
次に出てくんですが、/etc/slurm/slurm.confでDB管理機能は今はまだ無効化です。
なので現段階で意味はありませんが、先んじてStorageTypeパラメータはmysqlを利用するよう変更してます。 ユーザStorageUserとパスワードStoragePassは事前にmysqlにもユーザを準備して情報を合わせてあります。
StorageType=accounting_storage/mysql StoragePass=slurm StorageUser=xxxxx
/etc/slurm/slurm.conf
AccountingStorageEnforceはコメントアウト状態(デフォルト)で、アカウント機能はここで無効化された状態となります。
ちなみに”0"がインストール時に設定されていますがコメントアウトを解除しても有効な値ではありません。
またSlurmUserも、事前にOSユーザ(slurm)作成しておいたので設定しておきます。
AccountingStorageType=accounting_storage/none
#AccountingStorageEnforce=0
SlurmUser=slurm
Job実行用のユーザ作成
次にJob実行用に、OSユーザを作成します。
useradd -u 1002 johnuseradd コマンドでシンプルに「john」ユーザを作成 ※master,node1~4で作成します。
Jobスクリプトの準備
- 実行する為のJobスクリプトとして、適当に
test.sh、test-py-sort.pyを準備
#!/bin/sh #SBATCH -J test #SBATCH -p partition2 python3 ./test-py-sort.py
※割愛してますがtest-py-sort.pyはrandom.randint(0, 1000)で10000個の整数を発生させてsortするだけのサンプルプログラムです
ジョブ実行
では、sbatchでサンプルジョブを1回実行します。
[john@node1 ~]$ sbatch test.sh Submitted batch job 49
squeueで確認
[slurm@master ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
49 partition test john R 0:11 1 node3
→するとサンプルジョブで指定したpartition2のnode3で実行(ST=R)されている事がわかります。
つづいて、連続でジョブを何度か実行してみます。
[john@node1 ~]$ sbatch test.sh Submitted batch job 50 [john@node1 ~]$ sbatch test.sh Submitted batch job 51 [john@node1 ~]$ sbatch test.sh Submitted batch job 52 [john@node1 ~]$ sbatch test.sh Submitted batch job 53 [john@node1 ~]$ sbatch test.sh Submitted batch job 54
squeueで確認
[slurm@master ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
54 partition test john PD 0:00 1 (None)
50 partition test john R 0:16 1 node3
51 partition test john R 0:13 1 node3
52 partition test john R 0:13 1 node4
53 partition test john R 0:03 1 node4
→僕の環境リソース上、1nodeにつき2ジョブづつの実行になっていますが、リソースの許す限りpartition2(node3&4)でジョブが実行(ST=R)されている事がわかります。
※一度にさばけないジョブは保留(ST=PD)になっている事もわかります。
一応topコマンド
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 5269 slurm 20 0 65488 4460 3812 R 11.8 0.2 0:00.03 top→"slurm"ユーザでジョブが実行されていることがわかります。
動かしてみる(1)を終えて
...という事でアカウント機能の無効状態では、特にSlurmで何の関連付けもしていないOSユーザ「John」ユーザでsbatch実行可能な事が確認できました。
以降、アカウント機能を有効化する方法と挙動の変化を確認していきたいと思います。
アカウント機能の有効化
それではSlurmのアカウント機能有効化していきます。アカウント管理をSlurmDBD管理状態にする所から確認します。
設定ファイル
/etc/slurm/slurmdbd.conf
SlurmDBD管理を有効化します。
まずは/etc/slurm/slurmdbd.confを変更します。
# AccountingStorageType=accounting_storage/none AccountingStorageType=accounting_storage/slurmdbd
ちなみにAccountingStorageType=accounting_storage/noneの段階でsacctmgrなどの管理系コマンド(後述)を実行すると下記にようなメッセージが返ってきます。
[slurm@master ~]$ sacctmgr list cluster You are not running a supported accounting_storage plugin Only 'accounting_storage/slurmdbd' is supported.
/etc/slurm/slurm.conf
次に/etc/slurm/slurm.confも以下のように変更します。
#AccountingStorageEnforce=0 AccountingStorageEnforce=associations
→AccountingStorageEnforceというパラメータが出てきましたので、以降にもう少し詳しく見ていきましょう。
AccountingStorageEnforce
動かしてみる(1)で見た通り、適当に作成したOSアカウント(john)でsbatchジョブが実行可能でした。AccountingStorageEnforceパラメータを設定しない状況下ではユーザの実行可否は制御しないようなので、このオプションを有効化します。
有効なオプションは以下の通りで、オプションをカンマ区切りで列挙して組み合わせる事もできます。色んなオプションや組み合わせが考えられそうですが、少しづつ理解していきたいので、今回はassociationsを設定したいと思います。
AccountingStorageEnforce
| 設定例 | 内容 |
|---|---|
| associations | associaionsがデータベース(slurmdbd)に登録されていない場合、ユーザーはジョブ実行できない。associations登録がない=ユーザーは無効なアカウント扱い。 |
| qos | すべてのジョブが有効な QoS (Quality of Service) を指定することが、デフォルトで明示的に要求される。QoS値はデータベース内の各associationsに対して定義されます。このオプションを設定すると'associations'オプションが自動的に設定。QoSで制限を実施したい場合は、'limits' オプションを使用する必要があります。※QoSは後日(できれば) |
| limits | associationsに設定された制限が強制される。このオプションを設定すると、'associations' オプションも設定されます。 |
| nojobs | ジョブ情報をDB保存しない場合に設定 |
| nosteps | ジョブステップ情報をDB保存しない場合に設定 |
他にも,safe,wckeys...といった設定値が可能のようですが、機会があれば調べるとして(言っててやらないやつ)ひとまずは気にせず進めたいと思います。気になる方はドキュメント( Slurm Workload Manager -)を参照してください。
ここでassociationが登場しました。こちらももう少し詳しくみていきます。
associations
associationsとは、以下の4つの要素を組み合わせてグループ化した情報のこと。
これを利用環境にあわせて組み合わせてエンティティレコードとして登録し、各種リソース制限の付与対象として扱える機能がSlurmDBDの仕組みの一つ。 設定情報はデータベース(slurm_acct_db)に登録され、ここでMySQLが裏方として活躍することになります。
特定のパーティションに結びついたassociationsを作成することも可能で、Partition=sacctmgrというコマンドユーティリティがSlurmに用意されていて、 sacctmgr add account ~やsacctmgr create user ~などのコマンドを使用してデータを管理します。
associationsの利用イメージ
associationsは、階層構造で捉えるとわかりやすいかも知れません。
- Cluster → account → user→paritition(オプション)
を順に関連づけながらエンティティ(レコード)作成する。そうした作成されたassociationsに対して、リソース制限付与対象を管理することになる。という流れになるかと思います。
どんなことに適用できるか
すごく大雑把な例でいうと、「科学計算なんかをよく利用する会社」があってマシンリソースを研究者たちで共有する場合、associationを利用して部署(division)などの組織構成に合わせたリソース利用制限ができます。(MaxJobs=x)

親子関係 (account)
また、あるaccountに対して別accountを「親account」に設定する事ができ、以下のように組織が分化されているような場合でもassociationレベルでの制限構成を多層化する事もできるようです。
※今後のハンズオンで試してみたいと思います。

他にも、OSアカウント情報(ユーザ / グループ)なんかと紐付けて構成する管理手法もアリかと思います。
公開商用スパコン環境では請求情報などの管理にも使われている雰囲気です。
動かしてみる(2)
それでは、Slurmのアカウント機能を有効化しただけの状態でジョブを実行してみたいと思います。
#AccountingStorageType=accounting_storage/none AccountingStorageType=accounting_storage/slurmdbd
#AccountingStorageEnforce=0 AccountingStorageEnforce=associations
準備
以下をやっておきます。
/etc/slurm/slurm.confはnode1~4に配布してslurmdを再起動masterもslurmctldを再起動
ジョブ実行
では再度、johnユーザでジョブを実行します。
[john@node1 ~]$ sbatch test.sh sbatch: error: Batch job submission failed: Invalid account or account/partition combination specified
AccountingStorageEnforce=associationsの設定が効いていることがわかります。associationの情報登録がないjohnは、sbatchを実行することが出来なくなりました。
それではもう一度johnがSlurmを使えるように、「john」のassociationを設定していきます。
associationの作成
まずは以下を順に見ていくことにします。
- Cluster → account → user
※ひとまずassociationのパーティションについては今は考えません(勉強したら今後触れます)。
以下の組織構成例に沿って、sacctmgrを使ってjohnのassociationを作成してみたいと思います。

以下にように設定すれば良いイメージです。
| 内容 | 設定値 |
|---|---|
| cluster | sample-cluster |
| account | Chemistry |
| user | john |
Cluster
まずはclusterです。ひとまずsacctmgr list ~で初期状態を確認してみたいと思います。
[slurm@master ~]$ sacctmgr list cluster Cluster ControlHost ControlPort RPC Share GrpJobs GrpTRES GrpSubmit MaxJobs MaxTRES MaxSubmit MaxWall QOS Def QOS ---------- --------------- ------------ ----- --------- ------- ------------- --------- ------- ------------- --------- ----------- -------------------- --------- sample-cl+ 127.0.0.1 6817 9728 1 normal
アカウント機能を有効化した時点でsample-clusterというClusterレコードがすでに作成されているようです。 (Slurmが動く時点で、そらあもう設定済だろ、という話ですが)slurm.confの以下から自動的に生成されるようです。
ClusterName=sample-cluster
Clusterはこのままの設定を使うことにします。続いてaccountをみていきます。
account
次にaccountです。こちらも勉強という事で、sacctmgr list ~でひとまず初期状態を確認しておきます。
[slurm@master ~]$ sacctmgr list account Account Descr Org ---------- -------------------- -------------------- root default root account root
→こちもすでにrootというアカウントが作成されているようです。また、Descripitionによるとdefault root accountというようです。
では、今回はjohnが所属するaccountを作成してみたいと思います。
accountを追加する基本構文は:
sacctmgr add account <accountname>
以下オプション例(全てではないかもしれません)。
| オプション | 設定値 |
|---|---|
| Cluster= | 追加対象のクラスタを指定。アカウント管理DBでは複数クラスタを登録でき、デフォルトでは定義されたすべてのクラスタに追加される。 |
| Description= | アカウントの説明(デフォルトはaccount名が設定される)。 |
| Name= | accountの名前。ユニークである必要がある 。 |
| Organization= | accountの組織名。デフォルトは、親accountが設定されている場合は親account、そうでない場合はrootまたはaccount名が設定される。 |
| Parent= | すでに追加済のaccountを親に指定できる。 |
登録 ( account )
今回はParentなしで以下にように登録してみたいと思います。
sacctmgr add account Chemistry Cluster=sample-cluster Description="Chemistry departments" Organization=science.com
[slurm@master ~]$ sacctmgr add account Chemistry Cluster=sample-cluster Description="Chemistry departments" Organization=science.com Adding Account(s) chemistry Settings Description = chemistry departments Organization = science.com Associations A = chemistry C = sample-clu Settings Parent = root Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
結果を確認してみます。
[slurm@master ~]$ sacctmgr list account Account Descr Org ---------- -------------------- -------------------- chemistry chemistry departmen+ science.com root default root account root
[slurm@master ~]$ sacctmgr list associations format=cluster,account,user Cluster Account User ---------- ---------- ---------- sample-cl+ root
sample-cl+ root root sample-cl+ chemistry
では、このままuserの登録にすすみます。
user
次にuserです。こちらも勉強という事で、sacctmgr list ~でひとまず初期状態を確認しておきます。
[slurm@master ~]$ sacctmgr list user User Def Acct Admin ---------- ---------- --------- root root Administ+
→こちらも同様「root」ユーザが既に作成されています。デフォルトでrootユーザはassociationsが自動生成されるようです。
(もしかして /etc/slurm/slurm.confに制御項目があるのかもしれません)
では続いてuserを作成します。
userを追加する基本構文は:
sacctmgr add user <username>またはsacctmgr create user <username>で作成できるようで、オプション例は存在の通り(全てではないかもしれません)。
| オプション | 設定値 |
|---|---|
| Account= | ユーザーを追加するアカウント(複数可) |
| AdminLevel= | アカウントDBの更新権限。なし or Operator or Admin ※詳しくはdocで |
| Cluster= | 指定したクラスタ上のアカウントにのみ追加する(デフォルトは全クラスタ) |
| DefaultAccount= | ユーザのデフォルトアカウントで、ジョブ投入時にアカウントが指定されていない場合に使用。 |
| DefaultWCKey= | ユーザーのデフォルトのwckeyで、ジョブ投入時にwckeyが指定されていない場合に使用。※WCKeyは勉強不足なので今回は無視 |
| Name= | ユーザー名 |
| NewName= | アカウンティング・データベースでOSとは別ユーザー名にしたい場合に使用 |
| Partition= | associationが適用されるSlurmパーティションの名前です。 |
登録 ( user )
前述の通り今回はパーティションは気にせず、userは以下のように登録してみます。
sacctmgr add user john Cluster=sample-cluster Account=Chemistry DefaultAccount=Chemistry AdminLevel=Operator
[slurm@master ~]$ sacctmgr add user john Cluster=sample-cluster Account=Chemistry DefaultAccount=Chemistry AdminLevel=Operator Adding User(s) john Settings = Default Account = chemistry Admin Level = Operator Associations = U = john A = chemistry C = sample-clu Non Default Settings Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
確認してみます。
[slurm@master ~]$ sacctmgr list user User Def Acct Admin ---------- ---------- --------- john chemistry Operator root root Administ+
ではassociationsの結果もみてみましょう。
[slurm@master ~]$ sacctmgr list associations format=cluster,account,user Cluster Account User ---------- ---------- ---------- sample-cl+ root
sample-cl+ root root sample-cl+ chemistry
sample-cl+ chemistry john
→chemistry/johnが関連付いたレコードが出来ています。これで今回のjohnのassociationが作成できました。
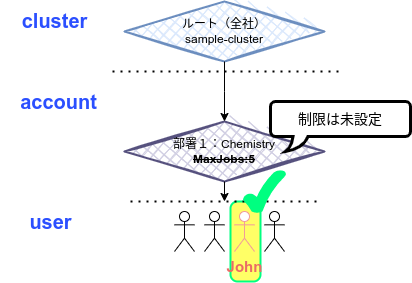
イメージ
先程作成したのは、以下のイメ➖ジです。
動かしてみる(3)
動かしてみる(2)では、アカウント機能を有効化した事でjohnがsbatchできなくなっていましたので、association設定で今度はjohnユーザがジョブ実行可能になっているか確認します。
実行
[john@node1 ~]$ sbatch test.sh Submitted batch job 61
[slurm@master ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
61 partition test john R 0:07 1 node3
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
6160 slurm 20 0 65488 4432 3784 R 5.9 0.2 0:00.02 top
→ ...という事で無事にjohnユーザがsbatchを実行できるようになった事が確認できました。
今回はこれで終了です。
最後に
- Slurmでアカウント機能を有効化
↓ - ユーザがジョブ(sbatch)を投げれない
↓ - associationsを設定
↓ - ユーザがジョブ(sbatch)を投げれるようになる
たったこれだけの事を長々と書いてしまいました
associationsを活用する場合、マシンリソースの制限が目的なことも多いかと想像しています。次回以降はそのあたりも勉強、整理して情報をまた残して行きたいと思います。