Slurm Installその後1.アカウンティング
はじめに
「Slurmをいい感じに使えるようにして♪」
※Slurm ・・・ HPC向けOSSジョブスケジューラ
少し前から↑な感じのことを言われてコツコツやっています。とりあえず構築してsbatchは動かせるけど、ジョブスケジューラ運用はやった事ないし「この後どうしていけば良いの?」...の状態でSlurmはよく理解出来ていないことが沢山です。(すくなくとも僕は)
これから、Slurmについてドキュメントやハンズオン(自前環境)で調べたことなど、情報整理がてらに残していきたいと思います。(例えば以下)
- Slurmで管理するアカウントやジョブ・リソース制限
- 「associations」や「QoS」といったキーワードや関連する諸々の設定
Slurm 公式はこちら slurm.schedmd.com
ちなみに
- オンプレ環境
- AWS(Parallel Cluster)今の所は触れません
目次
目的
Slurmのインストールが終わった状態からはじめます。ベストプラクティス的なものはわかりませんが、今回はまず「Slurmでのアカウント管理」としてassociationsの設定をみていきたいと思います。
シンプルかつ徐々に整理していきたいのでリソース制限は今回やりません(できれば次回以降)。
環境
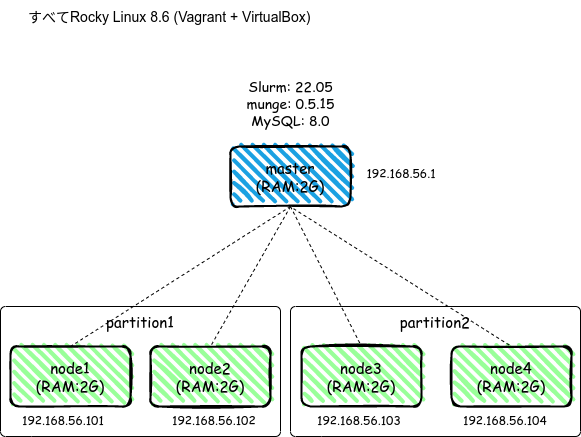
今回のハンズオン勉強用環境は先にざっくりまとめると
です。
SlurmCTLD/SlurmD
- Slurmのマスタ(slurmctld)・ノード(slurmd)は構築済みの前提
- 自宅マシン(Ubuntu22.04LTS)内でSlurm(master/node)はすべてVirtualBox
- GPU設定なし
- masterもnodeもすべてRocky Linux 8.6
- クラスタ名はsample-cluster
- node1~4を計算ノードとし、それぞれpartition1,2に分けるよう配置
※構成は今のところ意識する必要なし
SlurmDBD
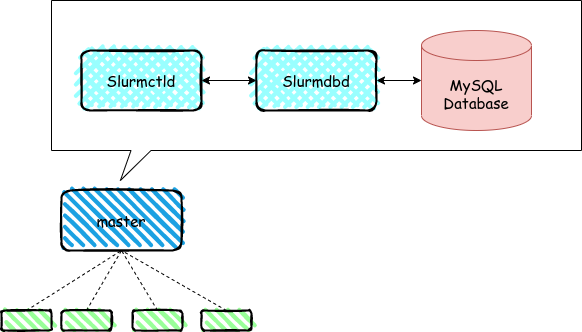
管理ノード(master)には以下も。
Slurmはジョブスケジューリング機能だけでなくアカウント管理やそれに関連付けたジョブ・リソースの制限を行う仕組みも内部に持っています。利用する為にはSlurmDBD/DB(MySQL)を準備しておく事が必要です。
ジョブ・ジョブステップの実行時の情報などもDBに記録されるようになります。※ジョブ・ジョブステップの実行情報はフラットなテキストファイルに記録可能で、SlurmDBDの構成は必須ではありません
今回はSlurmDBDを使って、Slurm内でユーザとアカウント間の「関連付け」の設定を理解していきたいと思います。
下の図はとてもざっくりですが、masterノード内のdaemonとMySQLは以下のように関連するイメージです。
動かしてみる(1)
素のインストール段階では、Slurmのアカウント機能は無効です。この状態でジョブ実行(sbatch)したときの動作を一度確認してみます。
Slurmのジョブ実行(sbatch)はOSアカウントがあれば、実行可能です。
準備
動かす前になんですが、以下3つを先にやっていきたいと思います。
- 設定ファイル確認
- Job実行用のユーザ作成
- Jobスクリプトの準備
設定ファイル確認
/etc/slurm/slurmdbd.conf
次に出てくんですが、/etc/slurm/slurm.confでDB管理機能は今はまだ無効化です。
なので現段階で意味はありませんが、先んじてStorageTypeパラメータはmysqlを利用するよう変更してます。 ユーザStorageUserとパスワードStoragePassは事前にmysqlにもユーザを準備して情報を合わせてあります。
StorageType=accounting_storage/mysql StoragePass=slurm StorageUser=xxxxx
/etc/slurm/slurm.conf
AccountingStorageEnforceはコメントアウト状態(デフォルト)で、アカウント機能はここで無効化された状態となります。
ちなみに”0"がインストール時に設定されていますがコメントアウトを解除しても有効な値ではありません。
またSlurmUserも、事前にOSユーザ(slurm)作成しておいたので設定しておきます。
AccountingStorageType=accounting_storage/none
#AccountingStorageEnforce=0
SlurmUser=slurm
Job実行用のユーザ作成
次にJob実行用に、OSユーザを作成します。
useradd -u 1002 johnuseradd コマンドでシンプルに「john」ユーザを作成 ※master,node1~4で作成します。
Jobスクリプトの準備
- 実行する為のJobスクリプトとして、適当に
test.sh、test-py-sort.pyを準備
#!/bin/sh #SBATCH -J test #SBATCH -p partition2 python3 ./test-py-sort.py
※割愛してますがtest-py-sort.pyはrandom.randint(0, 1000)で10000個の整数を発生させてsortするだけのサンプルプログラムです
ジョブ実行
では、sbatchでサンプルジョブを1回実行します。
[john@node1 ~]$ sbatch test.sh Submitted batch job 49
squeueで確認
[slurm@master ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
49 partition test john R 0:11 1 node3
→するとサンプルジョブで指定したpartition2のnode3で実行(ST=R)されている事がわかります。
つづいて、連続でジョブを何度か実行してみます。
[john@node1 ~]$ sbatch test.sh Submitted batch job 50 [john@node1 ~]$ sbatch test.sh Submitted batch job 51 [john@node1 ~]$ sbatch test.sh Submitted batch job 52 [john@node1 ~]$ sbatch test.sh Submitted batch job 53 [john@node1 ~]$ sbatch test.sh Submitted batch job 54
squeueで確認
[slurm@master ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
54 partition test john PD 0:00 1 (None)
50 partition test john R 0:16 1 node3
51 partition test john R 0:13 1 node3
52 partition test john R 0:13 1 node4
53 partition test john R 0:03 1 node4
→僕の環境リソース上、1nodeにつき2ジョブづつの実行になっていますが、リソースの許す限りpartition2(node3&4)でジョブが実行(ST=R)されている事がわかります。
※一度にさばけないジョブは保留(ST=PD)になっている事もわかります。
一応topコマンド
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 5269 slurm 20 0 65488 4460 3812 R 11.8 0.2 0:00.03 top→"slurm"ユーザでジョブが実行されていることがわかります。
動かしてみる(1)を終えて
...という事でアカウント機能の無効状態では、特にSlurmで何の関連付けもしていないOSユーザ「John」ユーザでsbatch実行可能な事が確認できました。
以降、アカウント機能を有効化する方法と挙動の変化を確認していきたいと思います。
アカウント機能の有効化
それではSlurmのアカウント機能有効化していきます。アカウント管理をSlurmDBD管理状態にする所から確認します。
設定ファイル
/etc/slurm/slurmdbd.conf
SlurmDBD管理を有効化します。
まずは/etc/slurm/slurmdbd.confを変更します。
# AccountingStorageType=accounting_storage/none AccountingStorageType=accounting_storage/slurmdbd
ちなみにAccountingStorageType=accounting_storage/noneの段階でsacctmgrなどの管理系コマンド(後述)を実行すると下記にようなメッセージが返ってきます。
[slurm@master ~]$ sacctmgr list cluster You are not running a supported accounting_storage plugin Only 'accounting_storage/slurmdbd' is supported.
/etc/slurm/slurm.conf
次に/etc/slurm/slurm.confも以下のように変更します。
#AccountingStorageEnforce=0 AccountingStorageEnforce=associations
→AccountingStorageEnforceというパラメータが出てきましたので、以降にもう少し詳しく見ていきましょう。
AccountingStorageEnforce
動かしてみる(1)で見た通り、適当に作成したOSアカウント(john)でsbatchジョブが実行可能でした。AccountingStorageEnforceパラメータを設定しない状況下ではユーザの実行可否は制御しないようなので、このオプションを有効化します。
有効なオプションは以下の通りで、オプションをカンマ区切りで列挙して組み合わせる事もできます。色んなオプションや組み合わせが考えられそうですが、少しづつ理解していきたいので、今回はassociationsを設定したいと思います。
AccountingStorageEnforce
| 設定例 | 内容 |
|---|---|
| associations | associaionsがデータベース(slurmdbd)に登録されていない場合、ユーザーはジョブ実行できない。associations登録がない=ユーザーは無効なアカウント扱い。 |
| qos | すべてのジョブが有効な QoS (Quality of Service) を指定することが、デフォルトで明示的に要求される。QoS値はデータベース内の各associationsに対して定義されます。このオプションを設定すると'associations'オプションが自動的に設定。QoSで制限を実施したい場合は、'limits' オプションを使用する必要があります。※QoSは後日(できれば) |
| limits | associationsに設定された制限が強制される。このオプションを設定すると、'associations' オプションも設定されます。 |
| nojobs | ジョブ情報をDB保存しない場合に設定 |
| nosteps | ジョブステップ情報をDB保存しない場合に設定 |
他にも,safe,wckeys...といった設定値が可能のようですが、機会があれば調べるとして(言っててやらないやつ)ひとまずは気にせず進めたいと思います。気になる方はドキュメント( Slurm Workload Manager -)を参照してください。
ここでassociationが登場しました。こちらももう少し詳しくみていきます。
associations
associationsとは、以下の4つの要素を組み合わせてグループ化した情報のこと。
これを利用環境にあわせて組み合わせてエンティティレコードとして登録し、各種リソース制限の付与対象として扱える機能がSlurmDBDの仕組みの一つ。 設定情報はデータベース(slurm_acct_db)に登録され、ここでMySQLが裏方として活躍することになります。
特定のパーティションに結びついたassociationsを作成することも可能で、Partition=sacctmgrというコマンドユーティリティがSlurmに用意されていて、 sacctmgr add account ~やsacctmgr create user ~などのコマンドを使用してデータを管理します。
associationsの利用イメージ
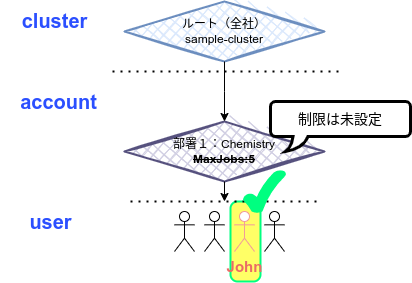
associationsは、階層構造で捉えるとわかりやすいかも知れません。
- Cluster → account → user→paritition(オプション)
を順に関連づけながらエンティティ(レコード)作成する。そうした作成されたassociationsに対して、リソース制限付与対象を管理することになる。という流れになるかと思います。
どんなことに適用できるか
すごく大雑把な例でいうと、「科学計算なんかをよく利用する会社」があってマシンリソースを研究者たちで共有する場合、associationを利用して部署(division)などの組織構成に合わせたリソース利用制限ができます。(MaxJobs=x)

親子関係 (account)
また、あるaccountに対して別accountを「親account」に設定する事ができ、以下のように組織が分化されているような場合でもassociationレベルでの制限構成を多層化する事もできるようです。
※今後のハンズオンで試してみたいと思います。

他にも、OSアカウント情報(ユーザ / グループ)なんかと紐付けて構成する管理手法もアリかと思います。
公開商用スパコン環境では請求情報などの管理にも使われている雰囲気です。
動かしてみる(2)
それでは、Slurmのアカウント機能を有効化しただけの状態でジョブを実行してみたいと思います。
#AccountingStorageType=accounting_storage/none AccountingStorageType=accounting_storage/slurmdbd
#AccountingStorageEnforce=0 AccountingStorageEnforce=associations
準備
以下をやっておきます。
/etc/slurm/slurm.confはnode1~4に配布してslurmdを再起動masterもslurmctldを再起動
ジョブ実行
では再度、johnユーザでジョブを実行します。
[john@node1 ~]$ sbatch test.sh sbatch: error: Batch job submission failed: Invalid account or account/partition combination specified
AccountingStorageEnforce=associationsの設定が効いていることがわかります。associationの情報登録がないjohnは、sbatchを実行することが出来なくなりました。
それではもう一度johnがSlurmを使えるように、「john」のassociationを設定していきます。
associationの作成
まずは以下を順に見ていくことにします。
- Cluster → account → user
※ひとまずassociationのパーティションについては今は考えません(勉強したら今後触れます)。
以下の組織構成例に沿って、sacctmgrを使ってjohnのassociationを作成してみたいと思います。

以下にように設定すれば良いイメージです。
| 内容 | 設定値 |
|---|---|
| cluster | sample-cluster |
| account | Chemistry |
| user | john |
Cluster
まずはclusterです。ひとまずsacctmgr list ~で初期状態を確認してみたいと思います。
[slurm@master ~]$ sacctmgr list cluster Cluster ControlHost ControlPort RPC Share GrpJobs GrpTRES GrpSubmit MaxJobs MaxTRES MaxSubmit MaxWall QOS Def QOS ---------- --------------- ------------ ----- --------- ------- ------------- --------- ------- ------------- --------- ----------- -------------------- --------- sample-cl+ 127.0.0.1 6817 9728 1 normal
アカウント機能を有効化した時点でsample-clusterというClusterレコードがすでに作成されているようです。 (Slurmが動く時点で、そらあもう設定済だろ、という話ですが)slurm.confの以下から自動的に生成されるようです。
ClusterName=sample-cluster
Clusterはこのままの設定を使うことにします。続いてaccountをみていきます。
account
次にaccountです。こちらも勉強という事で、sacctmgr list ~でひとまず初期状態を確認しておきます。
[slurm@master ~]$ sacctmgr list account Account Descr Org ---------- -------------------- -------------------- root default root account root
→こちもすでにrootというアカウントが作成されているようです。また、Descripitionによるとdefault root accountというようです。
では、今回はjohnが所属するaccountを作成してみたいと思います。
accountを追加する基本構文は:
sacctmgr add account <accountname>
以下オプション例(全てではないかもしれません)。
| オプション | 設定値 |
|---|---|
| Cluster= | 追加対象のクラスタを指定。アカウント管理DBでは複数クラスタを登録でき、デフォルトでは定義されたすべてのクラスタに追加される。 |
| Description= | アカウントの説明(デフォルトはaccount名が設定される)。 |
| Name= | accountの名前。ユニークである必要がある 。 |
| Organization= | accountの組織名。デフォルトは、親accountが設定されている場合は親account、そうでない場合はrootまたはaccount名が設定される。 |
| Parent= | すでに追加済のaccountを親に指定できる。 |
登録 ( account )
今回はParentなしで以下にように登録してみたいと思います。
sacctmgr add account Chemistry Cluster=sample-cluster Description="Chemistry departments" Organization=science.com
[slurm@master ~]$ sacctmgr add account Chemistry Cluster=sample-cluster Description="Chemistry departments" Organization=science.com Adding Account(s) chemistry Settings Description = chemistry departments Organization = science.com Associations A = chemistry C = sample-clu Settings Parent = root Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
結果を確認してみます。
[slurm@master ~]$ sacctmgr list account Account Descr Org ---------- -------------------- -------------------- chemistry chemistry departmen+ science.com root default root account root
[slurm@master ~]$ sacctmgr list associations format=cluster,account,user Cluster Account User ---------- ---------- ---------- sample-cl+ root
sample-cl+ root root sample-cl+ chemistry
では、このままuserの登録にすすみます。
user
次にuserです。こちらも勉強という事で、sacctmgr list ~でひとまず初期状態を確認しておきます。
[slurm@master ~]$ sacctmgr list user User Def Acct Admin ---------- ---------- --------- root root Administ+
→こちらも同様「root」ユーザが既に作成されています。デフォルトでrootユーザはassociationsが自動生成されるようです。
(もしかして /etc/slurm/slurm.confに制御項目があるのかもしれません)
では続いてuserを作成します。
userを追加する基本構文は:
sacctmgr add user <username>またはsacctmgr create user <username>で作成できるようで、オプション例は存在の通り(全てではないかもしれません)。
| オプション | 設定値 |
|---|---|
| Account= | ユーザーを追加するアカウント(複数可) |
| AdminLevel= | アカウントDBの更新権限。なし or Operator or Admin ※詳しくはdocで |
| Cluster= | 指定したクラスタ上のアカウントにのみ追加する(デフォルトは全クラスタ) |
| DefaultAccount= | ユーザのデフォルトアカウントで、ジョブ投入時にアカウントが指定されていない場合に使用。 |
| DefaultWCKey= | ユーザーのデフォルトのwckeyで、ジョブ投入時にwckeyが指定されていない場合に使用。※WCKeyは勉強不足なので今回は無視 |
| Name= | ユーザー名 |
| NewName= | アカウンティング・データベースでOSとは別ユーザー名にしたい場合に使用 |
| Partition= | associationが適用されるSlurmパーティションの名前です。 |
登録 ( user )
前述の通り今回はパーティションは気にせず、userは以下のように登録してみます。
sacctmgr add user john Cluster=sample-cluster Account=Chemistry DefaultAccount=Chemistry AdminLevel=Operator
[slurm@master ~]$ sacctmgr add user john Cluster=sample-cluster Account=Chemistry DefaultAccount=Chemistry AdminLevel=Operator Adding User(s) john Settings = Default Account = chemistry Admin Level = Operator Associations = U = john A = chemistry C = sample-clu Non Default Settings Would you like to commit changes? (You have 30 seconds to decide) (N/y): y
確認してみます。
[slurm@master ~]$ sacctmgr list user User Def Acct Admin ---------- ---------- --------- john chemistry Operator root root Administ+
ではassociationsの結果もみてみましょう。
[slurm@master ~]$ sacctmgr list associations format=cluster,account,user Cluster Account User ---------- ---------- ---------- sample-cl+ root
sample-cl+ root root sample-cl+ chemistry
sample-cl+ chemistry john
→chemistry/johnが関連付いたレコードが出来ています。これで今回のjohnのassociationが作成できました。
イメージ
先程作成したのは、以下のイメ➖ジです。
動かしてみる(3)
動かしてみる(2)では、アカウント機能を有効化した事でjohnがsbatchできなくなっていましたので、association設定で今度はjohnユーザがジョブ実行可能になっているか確認します。
実行
[john@node1 ~]$ sbatch test.sh Submitted batch job 61
[slurm@master ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
61 partition test john R 0:07 1 node3
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
6160 slurm 20 0 65488 4432 3784 R 5.9 0.2 0:00.02 top
→ ...という事で無事にjohnユーザがsbatchを実行できるようになった事が確認できました。
今回はこれで終了です。
最後に
- Slurmでアカウント機能を有効化
↓ - ユーザがジョブ(sbatch)を投げれない
↓ - associationsを設定
↓ - ユーザがジョブ(sbatch)を投げれるようになる
たったこれだけの事を長々と書いてしまいました
associationsを活用する場合、マシンリソースの制限が目的なことも多いかと想像しています。次回以降はそのあたりも勉強、整理して情報をまた残して行きたいと思います。